Training neural networks with larger batches in PyTorch: gradient accumulation, gradient checkpointing, multi-GPUs and distributed setups…
Productionizing and scaling Python ML workloads simply | Ray
Scale your compute-intensive Python workloads. From reinforcement learning to large-scale model serving, Ray makes the power of distributed compute easy and accessible to every engineer.
Source: Productionizing and scaling Python ML workloads simply | Ray
Building a Multi-User Chatbot with Langchain and Pinecone in Next.JS
In this example, we’ll imagine that our chatbot needs to answer questions about the content of a website. To do that, we’ll need a way to store and access that information when the chatbot generates its response.
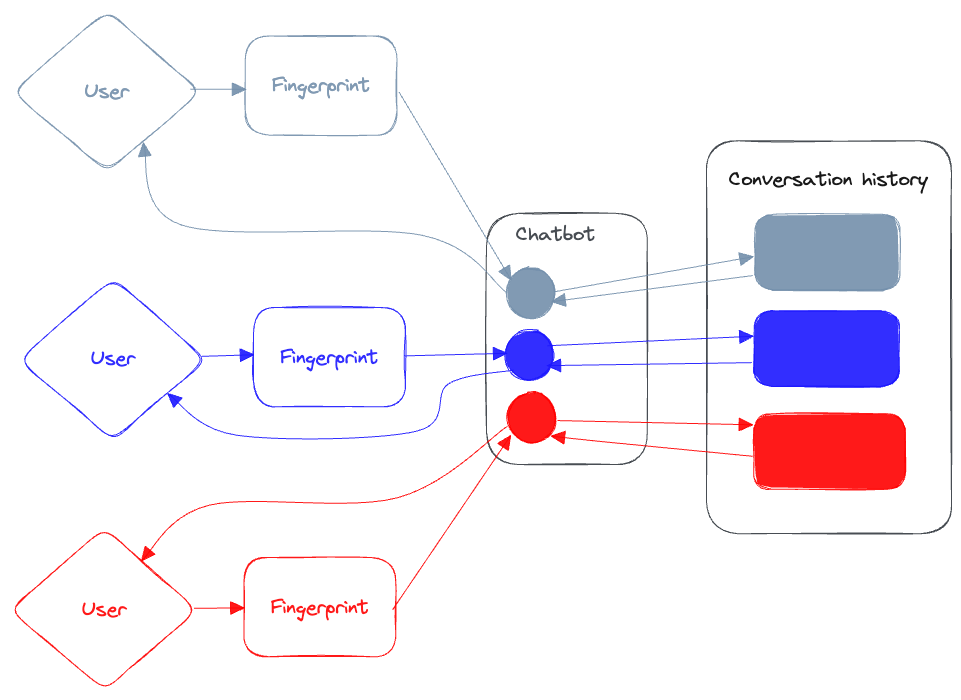
Source: Building a Multi-User Chatbot with Langchain and Pinecone in Next.JS
Mountpoint for Amazon S3 – Generally Available and Ready for Production Workloads | AWS News Blog
Mountpoint for Amazon S3 is an open source file client that makes it easy for your file-aware Linux applications to connect directly to Amazon Simple Storage Service (Amazon S3) buckets. Announced earlier this year as an alpha release, it is now generally available and ready for production use on your large-scale read-heavy applications: data lakes, machine learning training, image rendering, autonomous vehicle simulation, ETL, and more. It supports file-based workloads that perform sequential and random reads, sequential (append only) writes, and that don’t need full POSIX semantics.
— Mountpoint for Amazon S3 – Generally Available and Ready for Production Workloads
AudioCraft: A simple one-stop shop for audio modeling
AudioCraft is a simple framework that generates high-quality, realistic audio and music from text-based user inputs after training on raw audio signals as opposed to MIDI or piano rolls.
Source: AudioCraft: A simple one-stop shop for audio modeling
Meet Academic Standards With These Essential WordPress Plugins For Scholarly Content
Enhance your academic content’s credibility and make navigation of your articles easier on WordPress with these essential plugins.
Source: Meet Academic Standards With These Essential WordPress Plugins For Scholarly Content
Notes on better search 8/18/2023
Goal: better, more focused search for www.cali.org.
In general the plan is to scrape the site to a vector database, enable embeddings of the vector db in Llama 2, provide API endpoints to search/find things.
Hints and pointers.
- Llama2-webui – Run any Llama 2 locally with gradio UI on GPU or CPU from anywhere
- FastAPI – web framework for building APIs with Python 3.7+ based on standard Python type hints
- Danswer – Ask Questions in natural language and get Answers backed by private sources. It makes use of
- PostgreSQL – a powerful, open source object-relational database system
- QDrant – Vector Database for the next generation of AI applications.
- Typesense – a modern, privacy-friendly, open source search engine built from the ground up using cutting-edge search algorithms, that take advantage of the latest advances in hardware capabilities.
The challenge is to wire together these technologies and then figure out how to get it to play nice with Drupal. One possibility is just to build this with an API and then use the API to interact with Drupal. That approach also offers the possibility of allowing the membership to interact with the API too.
Demystifying Text Data with the unstructured Python Library | Saeed Esmaili
In the world of data, textual data stands out as being particularly complex. It doesn’t fall into neat rows and columns like numerical data does. As a side project, I’m in the process of developing my own personal AI assistant. The objective is to use the data within my notes and documents to answer my questions. The important benefit is all data processing will occure locally on my computer, ensuring that no documents are uploaded to the cloud, and my documents will remain private.
Demystifying Text Data with the unstructured Python Library — https://saeedesmaili.com/demystifying-text-data-with-the-unstructured-python-library/
To handle such unstructured data, I’ve found the unstructured Python library to be extremely useful. It’s a flexible tool that works with various document formats, including Markdown, , XML, and HTML documents.
AI Reading List 7/6/2023
What I’m reading today.
- Researchers from Peking University Introduce ChatLaw: An Open-Source Legal Large Language Model with Integrated External Knowledge Bases — This includes links to the article and Github repo
- Why Embeddings Usually Outperform TF-IDF: Exploring the Power of NLP
- Fine-tune an LLM on your personal data: create a “The Lord of the Rings” storyteller
- Open Assistant — In the same way that Stable Diffusion helped the world make art and images in new ways, we want to improve the world by providing amazing conversational AI. Github repo
Configuring Jupyter Notebook in Windows Subsystem Linux (WSL2) | by Cristian Saavedra Desmoineaux | Towards Data Science
Here’s a great quick start guide to getting Jupyter Notebook and Lab up and running with the Miniconda environment in WSL2 running Ubuntu. When you’re finished walking through the steps you’ll have a great data science space up and running on your Windows machine.
I am going to explain how to configure Windows 10 and Miniconda to work with Notebooks using WSL2